随着数据作为第五大生产要素被提出,“数据流通”的社会价值已形成广泛共识,由于行业背景、数据现状、研发能力等方面的差异性,不同行业企业对于“数据流通”的场景和诉求也不尽相同:
数据安全要求不同:有些企业相信中立的第三方,能接受数据安全上传至受信的第三方平台的方案;有些企业对数据保护较敏感,希望原始数据不流出自有网络和自有机器。
数据融合计算模式不同:有些场景需要统计分析的隐私计算能力,如双方数据求交后做SUM/COUNT等计算,或者双方联合SQL计算,最终得到统计分析结果;有些场景需要机器学习的隐私计算能力,如双方联合完成模型训练、模型预测,最终得到算法知识结果。
数据的云化程度不同:一些企业大部分业务系统已经上云,数据从产生到分析的全链路都在云平台完成,因此这类客户需要云上的解决方案来实现数据流通;还有很多企业的主要业务系统以及业务数据仍在自有IDC机房生成和加工处理,他们同样也有数据流通的需求场景。
数据计算和存储系统不同:对于一些数字化转型较早的企业,往往有完备的大数据计算和存储系统,如自建Hadoop、云上EMR、数据湖等,有现成的分布式计算和存储能力;还有一些企业,还没有完整的数据仓库体系,数据还保留在MySQL、PostgreSQL等业务数据库中,这种情况下所能提供的计算算力也比较有限。
数据所处的网络环境不同:隐私计算场景下,不同企业的数据存在于不同的网络环境内,企业内的数据处理系统一般是不对外提供服务的,因此大部分场景下多方之间的隐私计算过程需要通过公网传输数据;当然,也有如金融类企业愿意提供专线用于数据传输服务。
通过分析这些需求场景,我们不难得出以下几点结论:
隐私计算平台是典型的多学科交叉领域,涉及工程、算法、密码、硬件等多个方向,涉及统计分析、机器学习两大类应用场景,从广度和深度上系统架构的复杂度都很高,需要足够灵活的分层、分模块设计。
针对不同类型的场景和安全诉求,需要基于不同的隐私计算技术来提供解决方案,甚至需要同时结合多种隐私计算技术,形成一套解决方案来解决某一具体场景的问题。
安全合规是隐私计算技术和产品的重要依据,因此,隐私计算平台需要针对不同类型的数据融合计算场景,提供不同的隐私保护技术手段。
不同客户的数据分散在不同网络环境,大数据生态系统的现状也会千差万别,因此隐私计算平台对数据源、计算引擎、传输通道等组件的异构能力诉求是必然的,对云上部署、独立部署的能力也是基本要求。
DataTrust产品定位是通用的隐私计算产品,因此DataTrust工程技术架构能够同时支持多种隐私计算技术,严格遵循隐私计算安全标准,按照模块插件化的设计思路,适用于多种异构的计算、存储、网络环境,支持云上部署、独立部署等输出形态。
隐私增强计算技术
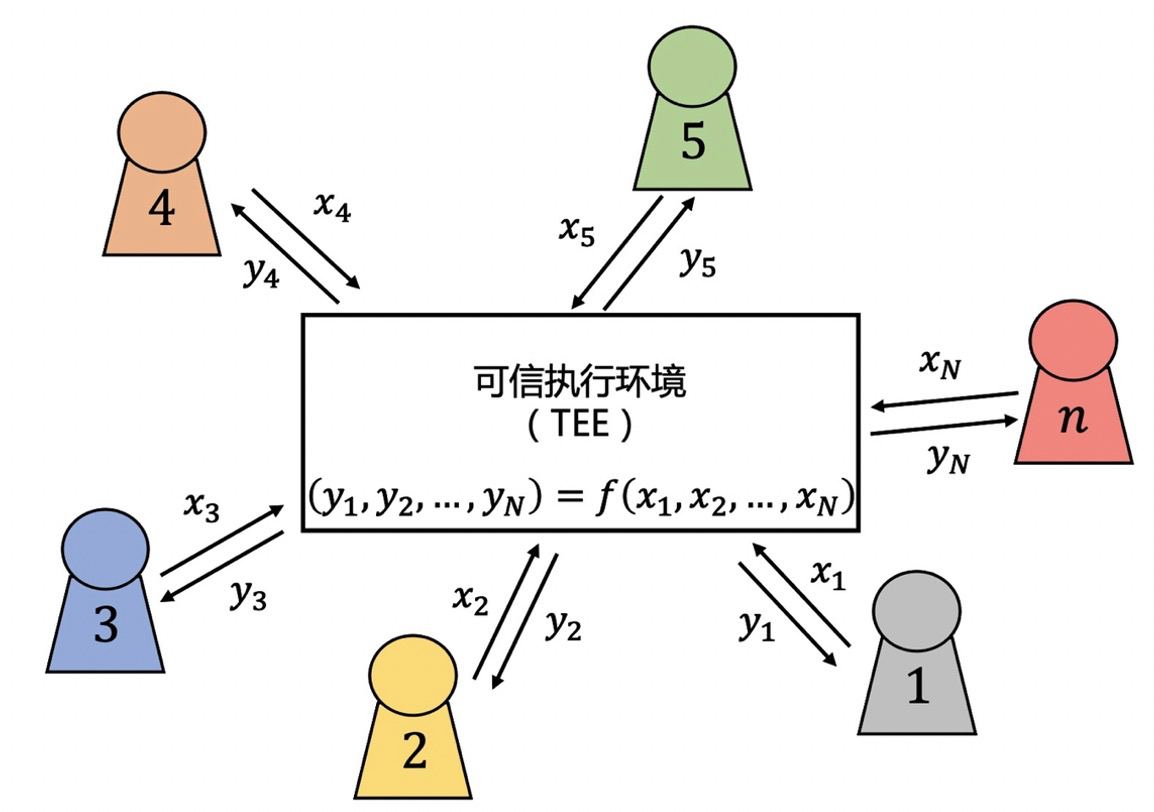
可信执行环境(Trusted Execution Environment,TEE)
TEE是硬件中的一个独立的安全区域,由硬件来保证TEE中代码和数据的机密性和完整性。也就是说,TEE是硬件服务提供商应用硬件在现实世界中构造的安全计算环境。应用TEE实现隐私增强计算的过程可以通过下图描述。
步骤1:各个参与方将自己的数据通过安全链路传输给TEE。
步骤2:TEE在保证机密性和完整性的条件下完成计算任务。
步骤3:TEE通过安全链路将计算结果发送给各个参与方。
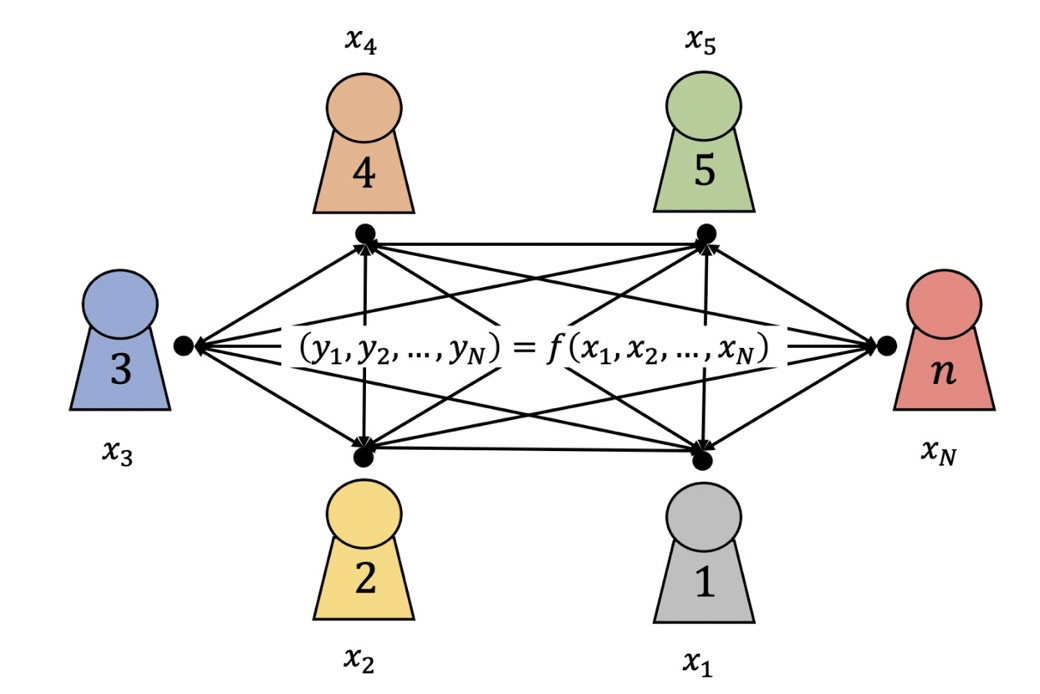
安全多方计算(Secure Multi-Party Computation,MPC)
MPC是密码学中的定义,在无可信计算方的情况下,多个参与方各自持有秘密输入,并可完成对某个函数的计算,但每个参与方最终只能得到计算结果和能从自己输入和计算结果中推出的信息,其他信息均可得到保护。安全多方计算的定义可以通过下图描述。
联邦学习(Federated Learning,FL)
联邦学习是一种多个参与方在保证各自原始私有数据不出数据方定义的私有边界的前提下,协作完成某项机器学习任务的机器学习模式。根据隐私安全诉求与训练效率的不同,可以通过MPC、同态加密(Homomorphic Encryption,HE)、差分隐私(定义见下)等多种方式实现联邦学习。
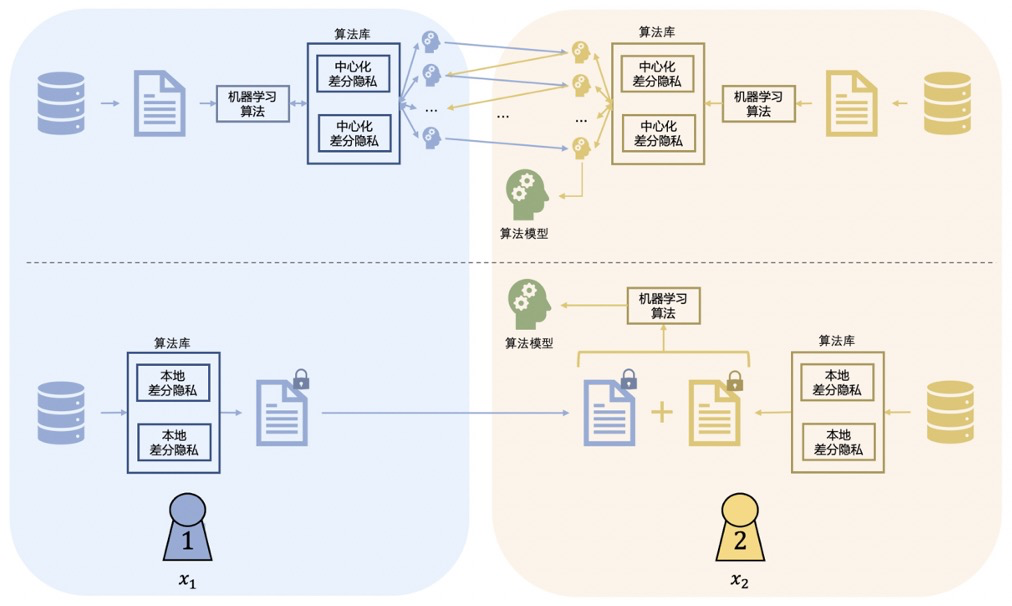
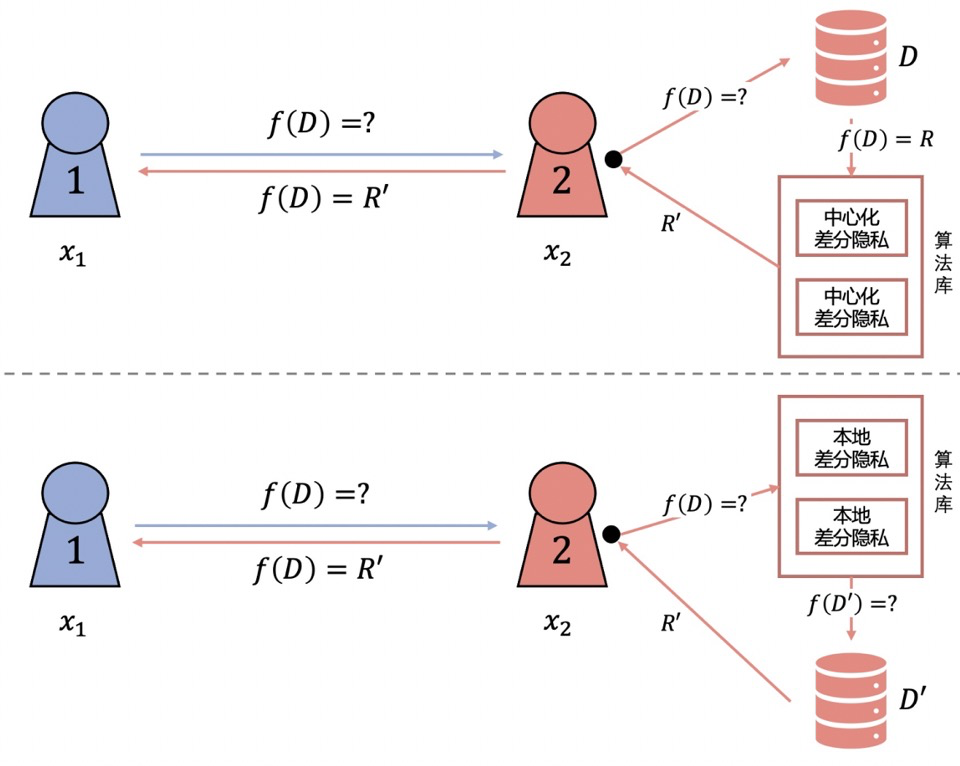
差分隐私(Differential Privacy,DP)
DP是一种基于对数据引入随机扰动,并从理论层面度量随机扰动所带来的隐私保护程度的隐私保护方法。根据随机扰动方式的不同,DP分为在原始数据层面进行随机扰动的本地差分隐私(Local Differential Privacy,LDP)和在计算结果层面进行随机扰动的中心差分隐私(Central Differential Privacy,CDP)。
以上几种常用的隐私计算技术,从工程架构角度可以划分为两类:
中心化的计算模式:即可信执行环境(TEE),在这种模式下,各参与方信任中立第三方,把原始数据安全加密后上传到TEE环境,并进行后链路的统计分析、机器学习等。涉及的技术领域除了TEE,还需要辅助RSA、AES等加密技术手段。
去中心化的计算模式:即安全多方计算(MPC)、联邦学习(FL)等,在这些模式下,各参与方不愿意把原始数据给到任何一方,包括任何第三方,各参与方按照多方计算的协议进行本地安全计算,传输协议数据、中间参数数据,最终完成联合的统计分析、机器学习等。需要特别说明的是,在去中心化的多方安全计算过程中,还是不可避免的需要有一个协调方的角色负责双方计算过程的协调、协议公共参数下发等过程,实际落地中,这个协调方可以由某一个参与方来承担,也可以由云平台、第三方来承担。涉及的技术领域除了MPC、FL,还需要辅助同态加密(HE)、差分隐私(DP)等技术。
DataTrust在工程架构设计阶段,抽象出“协调方”的角色,既能够在中心化场景下承担任务协调与中心化可信计算的职责,又能够在去中心化场景下承担多个计算方之间的任务协调职责,从而最终形成一套统一的技术架构支持不同类型的隐私计算技术,在安全性和架构统一性上取得了很好的平衡。在此基础上,进一步按照模块组件化设计,能够支持灵活的部署形态,具备各种异构环境下输出的能力。
DataTrust工程架构设计
基于以上思考,DataTrust隐私计算平台从功能模块上设计包含两个模块:
云上安全协调中心(Cloud Security Coordination Center,简称CSCC):以SaaS化服务部署在阿里云公有云或专有云,亦可独立化部署在客户私网环境,承担LSCC之间的任务协调调度、任务下发等协调性工作,同时还提供中心化的数据安全计算能力(即TEE可信执行环境)。
本地安全计算中心(Local Security Computation Center,简称LSCC):提供本地化数据源的管理、数据密钥管理、数字签名共识审批并提供本地化隐私增强计算能力,能保护客户原始数据不出域,因此需要在用户私网环境部署。
以下是DataTrust的工程技术架构图:
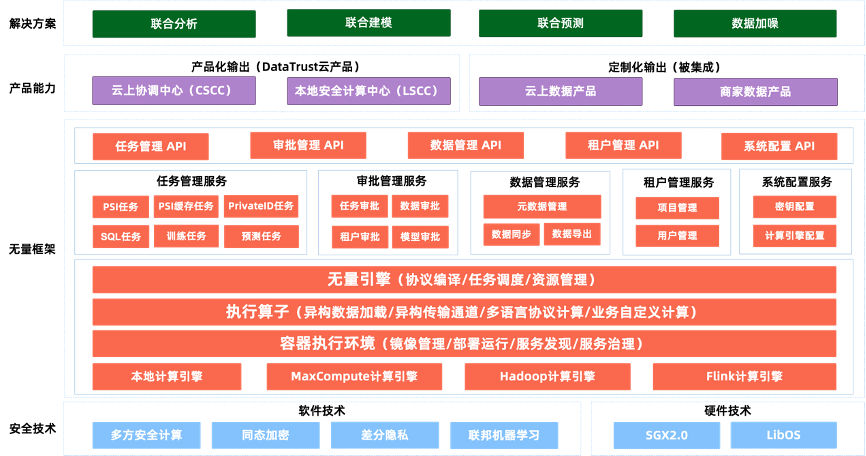
安全技术:底层基于不同类型的隐私计算技术,包括多方安全计算、同态加密、差分隐私、联邦学习等软件相关安全技术,以及SGX2.0等硬件相关安全技术;
无量框架:抽象和设计一套工程框架,向下统一支持不同类型的安全技术,向上依次提供三层能力:
– 引擎层:提供不同协议的编译过程、执行算子库等能力;提供任务调度执行相关能力,包括任务调度执行、资源管理、执行算子库等;提供不同类型计算引擎的抽象和管理能力;
– 服务层:面向产品功能提供服务实现,包括任务管理、审批管理、数据管理、租户管理、系统配置等;
– API层:基于中间服务层提供的服务能力,面向业务前台提供API接口能力;
产品能力:DataTrust通过云产品形式,输出标准化的产品能力(CSCC+LSCC),同时能够作为平台技术提供方,被第三方产品、客户方所集成,从而满足定制化的需求场景;
解决方案:从业务视角,面向客户提供联合分析、联合建模、联合预测等标准化的解决方案能力。
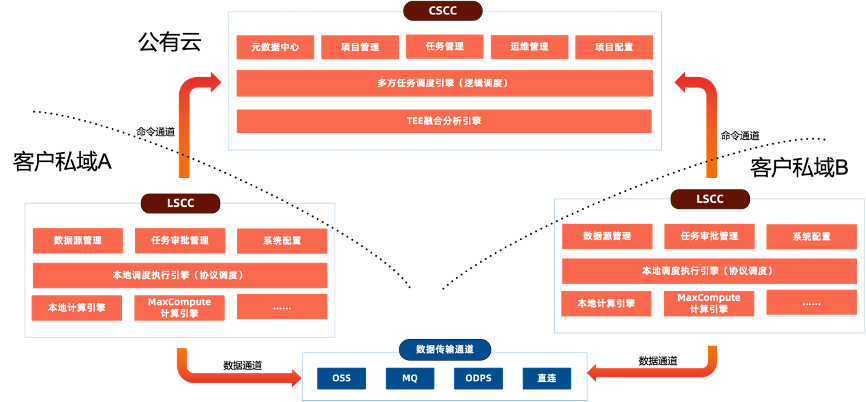
DataTrust在设计阶段,从逻辑上拆分为了CSCC和LSCC两个功能产品模块,针对不同的应用场景,在物理部署时可以灵活支持以下两种不同的部署形态:
云上部署架构:云上部署CSCC,客户在云上VPC或自有IDC机房等私域环境下部署LSCC。优点是各参与方无需部署和运维CSCC,由云平台作为第三方承担协调方的职责,各参与方仅需部署轻量化的LSCC即可完成本地安全计算。
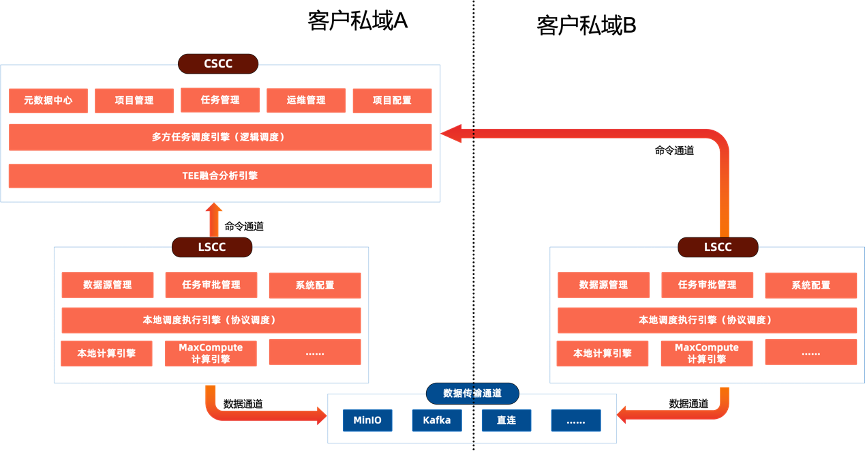
独立部署架构:一方客户在自有IDC机房等私域环境下部署CSCC+LSCC,另一方客户在自有IDC机房等私域环境下部署LSCC,双方点对点完成多方联合计算过程。该部署架构适用于金融等行业客户,希望能够不依赖于云平台、完全独立部署的场景。优点是无需引用云平台负责多方之间的协调职责,但前提是参与方之间一方信任另一方来承担协调职责。
DataTrust技术架构优势
严格遵循隐私计算安全标准
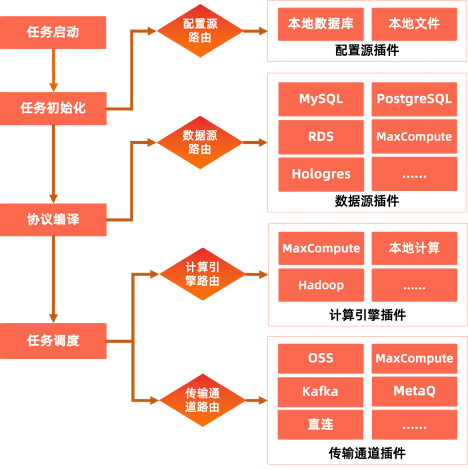
模块插件化、适配多种异构环境
遵循插件化的设计思路,随着支持业务落地过程中,目前已经支持了多种常见的配置源、数据源、计算引擎、传输通道等核心组件插件,而且能够快速扩展新的插件实现。
云原生容器化部署、多种部署交付形态
得益于灵活的技术架构、以及容器化的实现,DataTrust可以支持以下不同的部署形态:
– 云上部署:Client/Server模式
– 独立部署:Peer to Peer模式
– 一体机部署:软硬件一体机模式
– LSCC部署:单机模式(最小化部署)、集群模式(分布式部署)
包含协议密钥管理、协议编译、数据源管理、作业管理、作业调度执行等全链路产品化能力。
支持多租户的任务调度,支持即时调度、周期调度等调度方式。
业界领先的执行性能,超大规模数据场景下的稳定服务,且支持规模化服务客户。
大数据场景高性能及规模化– 完整的、系统化的商用云产品方案
– 灵活的平台开放能力
开放Open API,方便业务方集成开发、定制化开发场景。
开放执行算子开发框架,支持合作方、业务方自定义执行算子的开发与集成。
业务落地案例
DataTrust已具备MPC、FL、TEE等多种隐私计算技术下的联合分析、联合学习的产品化解决方案能力,目前已在多个业务场景完成落地。
联合分析:一方内容媒体侧和电商交易侧做全链路营销分析转化,用来指导产品和营销整体方案。
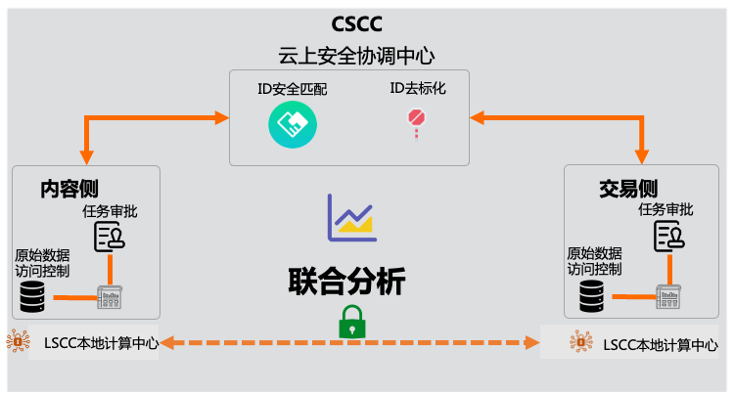
联合建模:广告主和媒体侧数据联合建模,提高转化率,用来指导投放策略。
以上是DataTrust在隐私计算领域从产品需求到工程架构的实践之路。
后续我们将从不同的产品功能方向,进一步和大家分享DataTrust的更多技术实现细节,敬请期待哦~
隐私增强计算平台DataTrust
DataTrust是行业领先的基于可信执行环境(Trusted Execution Environment,TEE)、安全多方计算(Secure Multi-Party Computation,MPC)、联邦学习(Federated Learning,FL)、差分隐私(Differential Privacy,DP)等隐私增强计算(Privacy Enhancing Technique)技术打造的隐私增强计算平台,在保障数据隐私及安全前提下完成多方数据联合分析、联合训练、联合预测,实现数据价值的流通,助力企业业务增长。

